Most “AI for dental insurance” pitches collapse under one question: where does the answer come from, and how do you know it’s right? Coverage determination — deciding whether a CDT code is covered, for this patient, at what cost — isn’t a single model call. It’s a data problem with two competing sources of truth, a reconciliation strategy, and an obligation to be honest about uncertainty. This is how ELVA’s RCM data engine is built, and why a system that sometimes says “I don’t know” is the one a DSO can build a decade on.
AI coverage determination is the process of deciding what a payer will cover and at what cost — and the architecture behind it matters more than the model. Here’s ours, at the depth a technical evaluator should demand from any vendor.
Two sources of truth, kept deliberately separate
There are two fundamentally different kinds of evidence about what a payer will cover, and most systems blur them. We don’t.
- What the payer says it does — published provider manuals, policy bulletins, state Medicaid manuals, ADA/CDT references, fee schedules. Authoritative and citable, but generic and frequently stale.
- What the payer actually does — the empirical record of how real claims adjudicated. Current and specific, but it has to be earned through volume.
Each covers the other’s blind spot. Stated policy answers the cold-start case where there’s no history; observed behavior catches the gap between what a payer publishes and what it pays. The two live in separate pipelines, with separate provenance, and are reconciled only at decision time — because the disagreement between them is itself one of the most valuable signals in the system.
Path 1 — Learning payer behavior from real claims
Every adjudicated claim becomes a normalized observation. Observations pool into cells of payer × plan × CDT code, and where the evidence supports it, ELVA derives a rule — across categories like allowed amount, cost-share, denial rate, frequency, bundling, downgrade, deductible exemption, missing-tooth clause, waiting period, and authorization or documentation requirements. Three design choices make this trustworthy rather than a black box:
- Confidence is earned, not assumed. A derived rule starts at medium confidence and is promoted only as additional claims corroborate it. Thin cells are explicitly recorded as gaps — not papered over with a guess.
- Rules are validated against held-out claims. A temporal holdout is split off and the derived ruleset is scored against claims it never saw — measuring whether rules generalize, not whether they memorized history.
- Cross-practice seeding has guardrails. A behavior observed consistently across many independent practices can seed a practice that hasn’t encountered it yet — but only above strict thresholds for organization count and claim count, so one practice’s anomaly never becomes everyone’s rule.
The result is a self-correcting model of each payer’s real behavior that strengthens with every remittance — the institutional knowledge a veteran biller carries, made auditable and shared.
Path 2 — Digesting the documents, with a judge in the loop
The document side is a full ingestion pipeline, not a prompt. A source document moves through tracked stages — preflight, OCR and layout parsing, normalization, semantic chunking — before any extraction happens. Then three controls apply:
- No citation, no rule. An extractor proposes candidate rules, each grounded to the exact source excerpt it came from. A rule that can’t point to its sentence doesn’t exist.
- A separate judge reviews every candidate. Each proposed rule is evaluated against validation checks and assigned a status — auto-accepted, rejected, or escalated for human approval. Nothing an extractor produces goes live without passing the judge. This is the single most important design decision on the document side: it’s what lets us use language models for extraction without inheriting their tendency to confabulate.
- Conflicts resolve by formal hierarchy. Surviving rules are scoped (payer, plan, jurisdiction, organization) and stamped with a source-authority tier. When two rules conflict, ADA/CDT references and state regulation outrank a payer FAQ; then scope specificity; then priority. Every state transition — created, approved, superseded, archived — is written to an audit chain.
Knowledge is also scoped from organization-specific up to ELVA-wide: curated global knowledge is the floor; a practice’s, state’s, or payer’s specifics override it. This is what it means for the platform to handle eligibility verification, prior authorization, and payer documentation requirements from one governed knowledge layer rather than a pile of PDFs.
The decision engine — and why it abstains
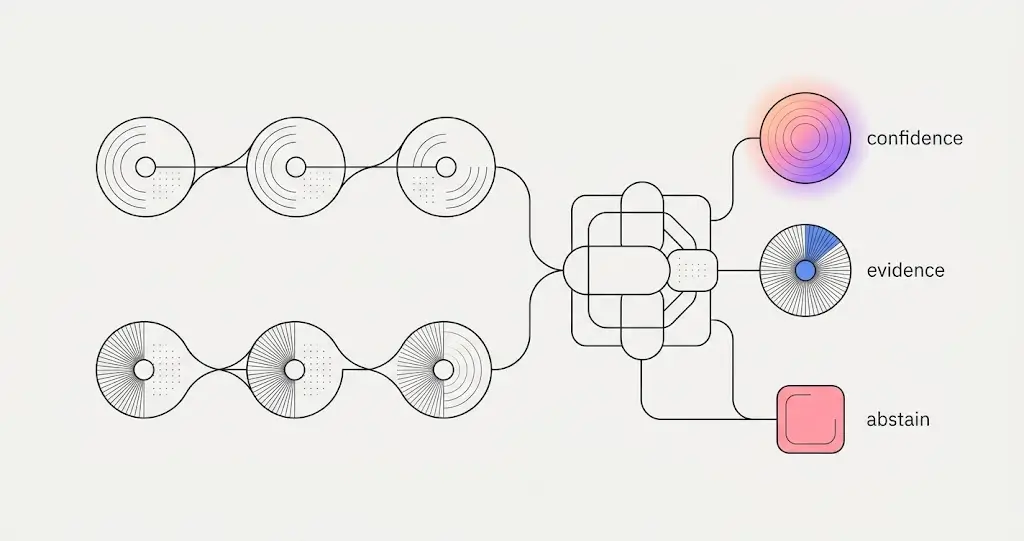
At query time, a single contract answers “is this CDT covered, for this patient, at what cost?” through a tiered search: direct eligibility first, then the derived and policy rules, then patient history. It returns not just an answer but a coverage state, a confidence level, the tier that produced it, and the evidence behind it.
The part we’re proudest of is what the engine does when the data doesn’t support an answer: it abstains. It has explicit states for “plan active, but no CDT-specific data,” “eligibility stale,” “request misrouted,” “payer unsupported.” A system that always answers is a system that is confidently wrong a predictable fraction of the time — and in RCM, a confidently wrong answer denies a real claim or misquotes a real patient. “I don’t know, and here’s why” is treated as a first-class, correct output — the same honesty-about-uncertainty discipline that runs through everything ELVA is allowed to do in a practice.
How we know it works
Anyone can ship a model. The differentiator is measurement, and ELVA’s is built like a test lab, not a demo. Ground truth is real adjudication outcomes — what the payer actually paid — on a patient-disjoint, temporally-forward split, so the system is never graded on data it could have memorized. Grading uses a confusion matrix, not a single accuracy percentage, because not all errors cost the same:
- The headline metric is the false-confident rate — answers that are wrong and high-confidence — weighted an order of magnitude more heavily than a cautious miss. That’s the cell that denies a real claim.
- Abstention is never counted as failure. Over-answering is tracked as its own metric; the model is never rewarded for guessing.
- Every probability is calibrated. Reliability curves and expected calibration error — when the system says 80%, it should happen about 80% of the time.
- Results are stratified by seen-vs-unseen payer, so a blended number can’t hide a model that’s strong on familiar payers and weak on new ones.
- The rule-extraction engine is measured separately — precision and recall of the rules it derives, not just final-answer accuracy — because a single wrong rule corrupts every downstream decision in its cell.
Why this is a foundation, not a feature
Three properties make the engine durable. Provenance everywhere: every fact traces to either a claim-volume-and-confidence trail or a source-document citation — which is what audits, appeals, and board-level scrutiny actually require. Self-correction: the behavioral model improves with every claim, and the document layer re-evaluates rules as feedback arrives. Honesty about uncertainty: the engine is engineered to know the boundary of what it knows. These are the properties that separate a system built as AI from one with AI bolted on — and they’re the same engineering standard behind the Practice Brain itself.
For a technical evaluator, three questions are worth asking any vendor: Where does each answer come from? Can it tell you when it doesn’t know? And can it prove it’s right against real adjudication outcomes — including on payers it has never seen? ELVA is built so the answer to all three is yes. See the full RCM platform at ELVA Insurance.
Frequently Asked Questions
How does AI coverage determination work?
A serious system reconciles two evidence sources at decision time: the payer’s stated policy (manuals, bulletins, fee schedules) and the payer’s observed behavior (how real claims actually adjudicated). Each answer should return a coverage state, a confidence level, the evidence behind it — and an explicit “I don’t know” when the data doesn’t support a confident answer.
Why does ELVA’s engine sometimes answer “I don’t know”?
Because a system that always answers is confidently wrong a predictable fraction of the time, and in RCM a confidently wrong answer denies a real claim or misquotes a real patient. Abstention — with the reason stated — is treated as a first-class correct output, and the engine is never rewarded for guessing.
How does ELVA stop a language model from inventing payer rules?
Two controls: every candidate rule must be grounded to the exact source excerpt it came from (no citation, no rule), and a separate judge evaluates every candidate against validation checks before anything goes live — auto-accepting, rejecting, or escalating to human approval.
How is the engine’s accuracy actually measured?
Against real adjudication outcomes on a patient-disjoint, temporally-forward split, graded with a confusion matrix. The headline metric is the false-confident rate — wrong and high-confidence — weighted far more heavily than a cautious miss, with calibrated probabilities and results stratified by seen-vs-unseen payer.
What should a DSO ask any RCM AI vendor?
Three questions: where does each answer come from (provenance)? Can it tell you when it doesn’t know (calibrated abstention)? And can it prove accuracy against real payer outcomes, including payers it has never seen? A vendor without good answers to all three is selling a demo, not a foundation.
Evaluate the foundation, not the demo. See ELVA Insurance, or the engineering story behind the wider system in how the Practice Brain is built.